Transactable World Models
By Robert Sun · Founding Engineer
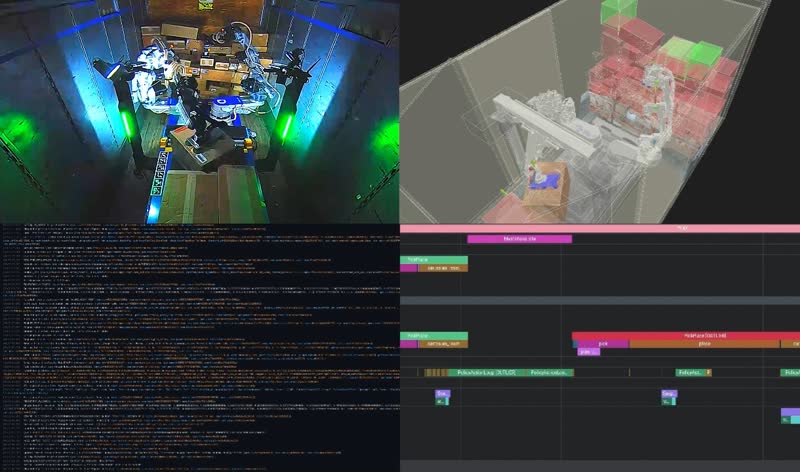
Dexterity’s path to Physical AI builds upon two foundations. The first is a team of asynchronous skill-agents that sense, think, and act upon the world through robots. The second is a foundational model that can act upon an interpretable set of historical observations about the world and predict how the world should behave and evolve in a manner consistent with physics.
Dexterity’s approach for the second foundation is to build “Transactable World Models”, which treat spatial understanding as a shared, physics-constrained operator against which multiple robot agents transact, guaranteeing explicit uncertainty bounds, rollback capability, interpretability, and real-time consistency.
Dexterity’s Physical AI architecture relies on an interpretable world model that connects asynchronous skill agents to reality. At Dexterity, we concluded that engineering simplicity entailed managing agentic communication with a system-of-record for transactions. In addition, a source-of-truth was valuable to abstract agent interaction with the world and provide an interpretable backbone to AI reasoning. Finally, we needed an ability to reason about physics. These challenges led us to build a transactable world model with a physics-integrable representation.
A world model functions as an operator that transforms the current world snapshot into an updated world snapshot, continuously building the world history. It is a key architectural element that provides a physics abstraction layer to agents. It also asynchronously publishes real time world updates. As such, it mediates agentic communication and is the ultimate arbiter of reality.
Our current focus is dexterous manipulation in enterprise applications using superhumanoid Mech robots as well as a variety of traditional robot arms. The world model architecture provides a strong foundation for AI models to be application agnostic and hardware agnostic. It does so by abstracting interactions with the real world to structured, yet interpretable, interactions from a robot to a digital simulation that provides spatial intelligence. It also simultaneously supports multiple agents.
World models today can support transaction guarantees to a wide variety of objects, including boxes, bags, containers, deformable plastic packaging, apparel and luggage. Each new object type adds new physics but leverages the same architectural foundation.
To manipulate objects—to grasp them, move them, place them, stack them—an AI must understand space in a way that transcends passive observation. The system must know: Where exactly is each face? What is its precise orientation? Which surfaces are accessible? How does various lighting affect the observation? How does it relate spatially to every other object? Is it stable or precarious? Is it in the foreground or background? Can I reach it without colliding with it or the environment? Will it support another object if I place one atop it?
This is spatial intelligence—not merely perceiving geometry, but understanding it deeply enough to interact with confidence.
A human can glance at such a pile and immediately grasp its structure—which boxes rest on which, where stable placement zones exist, how the configuration might shift if one box is removed. This understanding is so effortless for humans that we underestimate its computational depth. For AI, it represents a formidable inference problem.
AI must somehow fuse fragmentary multi-view observations into complete, coherent three-dimensional object representations. It must reason backward from what is seen to what must exist but cannot be seen. It must handle radical uncertainty—is that partially visible edge part of one large box or two smaller ones? It must maintain temporal consistency as viewpoints shift and objects move. And critically, it must do all this in a way that supports physical interaction: the estimated geometry must be accurate enough that a robot arm can reach, grasp, and manipulate based on it.
Passive scene understanding—the kind that powers object recognition or autonomous navigation—can tolerate significant geometric imprecision. But manipulation demands millimeter-level accuracy in pose, correct identification of graspable surfaces, and reliable prediction of how objects will respond to applied forces.
Physical AI doesn’t just observe—it acts. Every action changes the world. A robot grasps a box, moves it, places it down. The pile shifts. Previously hidden surfaces become visible. Previously stable configurations become unstable. Sensor occlusions change. The world model must continuously ingest not only new sensor observations but also the results of physical actions—both successful and failed.
When a manipulation succeeds, that outcome provides valuable evidence: the object was indeed where we thought, its properties matched our model, the physics unfolded as predicted. When a manipulation fails—the grasp slips, the box topples, contact occurs earlier than expected—that failure is equally informative. It tells us our world model was wrong in specific, actionable ways.
However, different agents that interact with the physical world operate at different timescales and latencies, which forces the world model and its exchange with these agents to operate asynchronously. One agent may be processing the world state for long term planning while another executes a grasp while a third prepares for a tight placement—all concurrently, all transacting against the same world model.
The distinction between treating world models as operators versus data stores is fundamental to enabling reliable Physical AI.
Many contemporary world models function as sophisticated compression and replay systems. They learn to reproduce sensor data—generating different camera views of a scene, interpolating environmental conditions, or synthesizing plausible observations. These systems excel at storing and reconstructing past observations, essentially acting as learned databases that compress training data for efficient retrieval and re-rendering. Neural radiance fields (NeRFs), video generation models, and sensor reconstruction networks fall into this category. They answer the question: “What did the world look like?”
This paradigm fails for manipulation because: No causal reasoning: They reproduce correlations from training data without understanding physical cause-and-effect. No physics grounding: Generated outputs may violate physical laws, contain impossible configurations, or hallucinate plausible but incorrect geometry. No uncertainty quantification: Confidence is implicit in generation quality, not explicitly reasoned about. No transaction guarantees: Cannot commit to interpretable, verifiable outcomes required for multi-agent coordination.
Dexterity’s world models function as operators that transform and reason about physical reality. An operator takes as input the current world snapshot (the physics-integrable representation at time t), new multi-modal sensor observations, robot body-state, and interaction outcomes—and produces as output an updated world snapshot at time (t+1), continuously building the world history.
Critically, the operator must have learned the causal effects of reality across all encountered scenarios. It interprets incoming data—disambiguating what is real, what is sensor noise, what is physically impossible—rather than simply decompressing pre-recorded patterns. When a robot manipulates an object and the outcome contradicts visual estimates, the operator reasons about which hypothesis failed and updates the physics-grounded world snapshot accordingly.
This paradigm enables manipulation because: Causal understanding: Reasons about cause-and-effect relationships required for predicting interaction outcomes. Physics integration: Every world snapshot must satisfy volumetric constraints, contact relationships, and stability conditions. Explicit uncertainty: Quantifies confidence bounds that enable risk-aware decision-making by downstream agents. No hallucination: Produces interpretable, verifiable world snapshot updates with rollback guarantees.
The operator paradigm is orders of magnitude more difficult to build than data storage systems, but it is the only approach that provides the interpretability and physical consistency guarantees required for transactable world modeling. When multiple agents coordinate based on shared understanding, when manipulation success depends on millimeter-level accuracy, when safety requires verifiable bounds on behavior—storing and replaying observations is categorically insufficient. The world model must actively reason about physics at every timestep, transforming raw sensor input into physics-consistent World Snapshots that agents can transact against with explicit uncertainty and rollback capabilities.
This is why Dexterity’s world models enable production-level reliability in dense manipulation scenarios where other approaches fail: they are operators that reason about reality, not databases that compress it.
Our architectural commitment to Compositional Transactions imposes specific requirements on world models, which enable them to be used in an agentic Physical AI system: In order to maintain a reliable and interpretable world model for agents to work against, and for roboticists to understand behavior, we have several concepts that drive what we do.
Physics-Integrable world snapshot: The world model must support extracting a world snapshot from the world history. This world snapshot should fully capture the integrable state at a given point of time. It should also support reasoning about volumetric constraints, contact relationships, stability, and dynamics. Estimated states must decide to be physically plausible—objects cannot float, intersect arbitrarily, or violate known environmental constraints (such as moving too quickly or changing shape) when needed.
Explicit Uncertainty Quantification: Since multiple agents interact with the world model concurrently, and transactions commit at different times than when sensor data was gathered, uncertainty must be represented explicitly. Agents must be able to query confidence levels and make risk-aware decisions. An agent planning a delicate manipulation needs to know: Is this object’s size confident to ±2mm or ±20mm for a robust motion? Should I trust the neighboring boxes if it’s going to be a tight squeeze? How likely will other boxes shift if this box is moved? If I suction grasp this box, how likely is it that neighboring objects also get attached? The difference determines what actions are viable.
Multi-Modal Fusion with Interaction Feedback: Operating on world snapshots cannot rely solely on passive sensing. It must integrate observations from multiple sensor modalities with outcomes from physical interactions. When a robot touches a surface and measures contact forces, that tactile feedback provides ground truth that refines or contradicts visual estimates. When a grasp fails, the failure mode informs what was wrong about the geometric estimate.
Temporal Consistency Under Asynchronicity: The world history stores a log of agent sensing and action results. World snapshots must be temporally ordered and causally consistent (impossible things cannot happen due to sequencing), even when transactions arrive asynchronously and out of order with respect to physical execution time. Different agents operate at different frequencies—vision at 10Hz, motion control at 1kHz, task planning at 1Hz—yet all must maintain a coherent view of the world state.
Being able to use modularity and controls to our advantage when engineering complex AI systems is a huge factor to our design. The principles to composition do not define the implementation, but serve just as a guideline for what kind of controls should be available in an AI system.
Transactions with Pre-Specified Outcomes: State updates commit with explicit success criteria—pose estimates within specified confidence bounds, physical plausibility verified, multi-sensor consistency validated. If these criteria cannot be met, the transaction reports failure with diagnostic information, enabling rollback to prior state.
Rollback and Recovery: When the world model fails validation—excessive uncertainty, physical inconsistency, contradictory observations—we revert to prior states and flag regions requiring re-observation or alternative sensing modalities.
Internal Compositional Simplicity: Rather than an end-to-end black box from sensors to world snapshot, we can compose interpretable components that transact with each other: sensor processing, observation clustering, geometric inference, physical validation, confidence calibration. Each component produces interpretable outputs that can be logged, debugged, and validated independently.
Support for Asynchronous Agents: Explicit timestamps, uncertainty bounds, transaction logs, and provenance tracking enable multiple agents to interact with the world model concurrently while maintaining consistency. Agents can query: when was this estimate produced? From which sensors? How reliable is it? Has it been validated by interaction?
Position-Invariant Transactions: Explicit uncertainty representation directly enables position-invariant success criteria. An agent can specify: “success if object ends up in target region ±δ” and the world model’s confidence bounds inform whether this can be verified.
Production-level Reliability and Enterprise Safety: In deployed operations, the transactable world model enables >96% one-shot successful manipulation in dense, occluded scenarios and provides safety guarantees unachievable by traditional foundation models.
Rather than seeking a single “best” configuration, we maintain distributions over plausible snapshots, explicitly representing where confidence is high and where uncertainty dominates.
Sensing agents take raw data and transact against the world model. A real, potentially noisy measurement needs to remain consistent with physics and reality, with uncertainties and physical phenomena/properties marked explicitly in object data. Each modality provides partial, noisy evidence. Visual and depth data may be ambiguous, sparse, or noisy. Segmentation may fragment objects or merge distinct entities. Temporal predictions drift. But their fusion—weighted by reliability and cross-validated for consistency—produces estimates far more robust than any single source.
Critically, interaction feedback grounds these estimates in physical reality. When a robot grasps an object, contact forces and tactile feedback provide direct measurement of where surfaces actually exist, not where vision predicted they might exist. When a box is placed and remains stable, that outcome validates both the geometric estimate and the stability prediction. Failed interactions are equally valuable: they definitively rule out hypotheses that passive sensing alone might have retained.
The physical interpretation problem can be thought of as an optimization under constraints: find configurations that best explain observations while satisfying physics to the best degree. Objects can be arranged in any number of ways. Occlusion creates hard limits on information. All the while giving the other agents within Dexterity’s system the best chance to succeed, which means a degree of co-optimization as well.
The optimization must balance competing objectives: Observational fidelity: configurations should match sensor data and noise. Physical plausibility: objects must obey volumetric constraints, contact models, stability conditions. Temporal coherence: physical entities should move/morph/evolve smoothly unless evidence demands abrupt change. Uncertainty calibration: confidence should reflect actual reliability, neither overconfident nor needlessly conservative.
It is inevitable that no world model is perfectly up-to-date with reality. Even for human perception, visual, auditory, and tactile stimuli are received and processed at different timescales and with different latencies within the brain’s neural network. What an agent can do with relatively recent but uncertain information is entirely up to the discretion of the agent.
Fundamentally, this constraint encapsulates a promise of interpretability. This makes it a valuable tool to help project futures given the reality of always-stale world models.
Good transaction agents know about this intrinsically, and offer “open-ended” ingresses into the skill, dramatically improving their success rate.
While our approach achieves production-level reliability in real-world logistics operations, understanding for dense object arrangements remains fundamentally challenging: Extreme Occlusions: When many objects stack high or nest deeply, observability drops precipitously. Some objects may be entirely hidden from all sensor views for extended periods. There are also regularly occlusions created by the robot itself since the arms and hands can block the camera’s field of view. The world model must gracefully handle this by maintaining prior estimates with appropriately increased uncertainty while opportunistically updating whenever glimpses become available.
Object Homogeneity: Identical objects viewed from multiple angles create ambiguous correspondences. Which observation corresponds to which object? Temporal tracking helps but becomes unreliable when objects move during manipulation or when visual similarity defeats correspondence algorithms.
Deformability and Non-Rigidity: Our rigid-body assumption breaks for soft packaging, deformable containers, or articulated structures. Extensions to handle non-rigid objects require substantially richer representations and more complex physical models.
Real-Time Performance: Meeting control loop deadlines while processing high-dimensional multi-modal sensor data and solving constrained optimization problems necessitates aggressive algorithmic and computational optimization. This is an ongoing engineering challenge.
Our approach embraces these challenges by quantifying uncertainty explicitly and propagating it to downstream agents who reason about risk appropriately and avoid hallucinating false confidence.
Building transactable world models for Physical AI requires more than accurate perception—it requires architectural commitment to interpretability, physical consistency, explicit uncertainty representation, and integration of interaction feedback. The challenge of understanding the world the robots manipulate showcases why spatial intelligence for robotics differs fundamentally from passive scene understanding. Manipulation demands: Millimeter-level geometric accuracy, not coarse object recognition. Physical plausibility, not just visual coherence. Uncertainty quantification, not point estimates. Integration of interaction outcomes, not just passive sensing. Real-time responsiveness, not offline inference.
Direct end-to-end models and perception without specific architecture like Dexterity’s world models may achieve impressive results but offer no interpretability about where and why they succeed or fail. When multiple agents must coordinate based on shared world understanding, when safety requires bounded behavior, when interaction outcomes must be integrated—interpretability becomes foundational, not optional.